
https://www.acmicpc.net/problem/10751
코드
let fs = require("fs");
let filePath = process.platform === "linux" ? "dev/stdin" : "./input.txt";
let [n, word] = fs.readFileSync(filePath).toString().trim().split("\n");
function solution(n, word) {
let cow = Array.from(new Array(n), () => new Array(3).fill(0));
if (word[0] === "C") {
cow[0][0] = 1;
}
for (let i = 1; i < n; i++) {
cow[i] = cow[i - 1].slice(0, 3);
switch (word[i]) {
case "C":
cow[i][0]++;
break;
case "O":
cow[i][1] += cow[i - 1][0];
break;
case "W":
cow[i][2] += cow[i - 1][1];
}
}
return cow[n - 1][2];
}
console.log(solution(n, word));
코드 설명
우선 입력된 단어를 word라는 변수에 저장했다고 했을 때, word의 i번째 글자까지 만들 수 있는 "C", "CO", "COW"의 개수를 저장할 2차원 배열 cow를 만든다. cow[i]의 0번째는 "C", 1번째는 "CO", 2번째는 "COW"를 뜻한다.
예를 들어, CCOOWW가 있다고 할 때, cow[4]에는 [2, 4, 4]이 저장된다. CCOOWW까지 "C"는 2개를 만들 수 있고, "CO"는 4가지(0번째 C+2번째 O, 0번째 C+3번째 O, 1번째 C+2번째 O, 1번째 C+3번째 O), "COW"는 앞선 "CO"에 5번째 W를 붙이는 경우 4가지를 만들 수 있다.
for문을 돌며 이 cow 배열의 값을 cow[1]부터 cow[n-1]까지 채운다. 여기서 for문의 인덱스가 0이 아닌 1부터 시작하는 이유는 for문 내를 보면 i-1의 값을 사용하기 때문이다. 그렇기에 cow[0]은 for문 이전에 처리를 해준다.
cow[i]의 값은 cow[i-1]에서 복사해오고, word[i]의 값에 따라 switch문을 이용하여 각 케이스에 맞는 코드를 실행한다. 만약 word[i]가 "C"라면 cow[i][0]을 1 증가시켜주고, word[i]가 "O"라면 이번 문자와 앞에 존재하던 "C"들이 결합하여 "CO"가 되는 경우가 발생하는 것이므로 cow[i][1]에 cow[i-1][0]의 수를 더해준다. 그리고 word[i]가 "W"라면 앞에 존재하던 "CO"와 이번의 "W"가 결합하여 "COW"가 완성되는 경우를 구하기 위해 cow[i][2]에 cow[i-1][1]의 값을 더해준다.
이렇게 for문을 n-1 인덱스까지 실행하고 난 뒤 cow[n-1][2]의 값이 cow를 완성할 수 있는 경우의 수다.
문제 & 해결
처음에는 코드의 13번째 줄 부분을 아래와 같이 작성했다.
cow[i] = cow[i - 1];
이렇게 작성한 뒤에 디버깅을 하며 cow 배열의 값을 확인해봤더니 아래와 같이 복사한 배열을
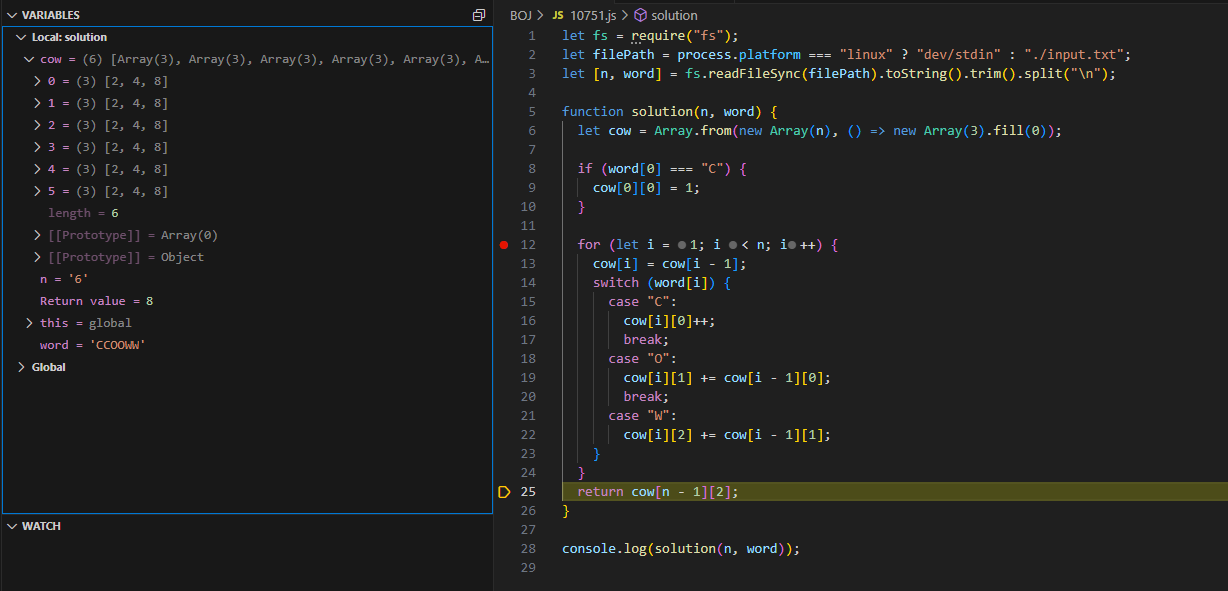
사실 이렇게 작성해도 코드의 작동에는 문제가 없었지만, cow[i]에는 word의 i번째 글자까지 봤을 때 만들 수 있는 "C", "CO", "COW"의 개수를 저장하겠다고 했던 설계와 달라지기 때문에 다음과 같이 slice 메서드를 이용하여 cow[i-1]의 값을 가져오도록 변경했다.
cow[i] = cow[i - 1].slice(0, 3);
근데 찾아보니 slice를 이용한 복사도 얕은 복사였다....근데 slice로 변경한 뒤에 디버깅을 하며 cow의 값을 확인해봤을 때는 아래와 같이 이전 배열의 값이 변경되지 않았다.
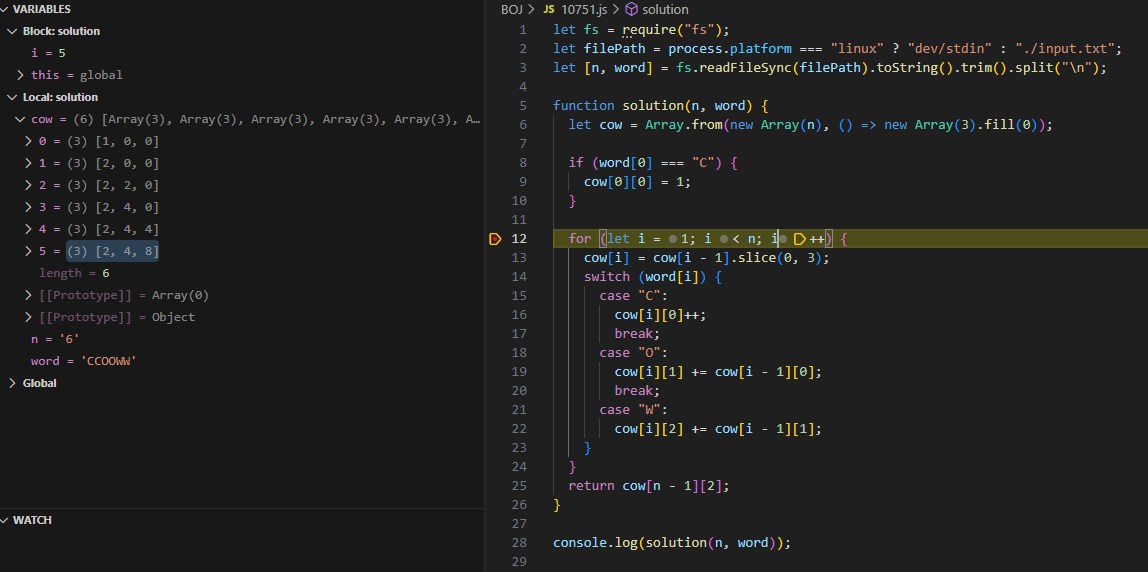
얕은 복사랬는데 왜 복사본의 값을 변경해도 원본 배열의 값이 바뀌지 않는걸까?
모르겠어서 chatGPT에게 물어봤다.
여기서 중요한 점은 cow[i] = cow[i - 1].slice(0, 3);입니다. 이 줄은 cow[i]가 cow[i - 1]의 얕은 복사본이 되도록 합니다. cow[i - 1]의 각 값(예: cow[i - 1][0], cow[i - 1][1], cow[i - 1][2])이 그대로 cow[i]에 복사됩니다. 하지만 이 경우 각 값(숫자)은 원시 값이므로, 복사된 값은 새로운 배열의 각 인덱스에 개별적으로 존재하게 됩니다.
즉, 원시 값을 가지는 배열에서 slice를 사용하면, 각 인덱스에 대한 참조가 아닌 값 자체가 복사되기 때문에 원본 배열은 영향을 받지 않습니다.
chatGPT가 설명을 정말 길게 잘해줬지만, 핵심만 갖고 왔다. 정리해보자면, 원시 값만을 갖는 배열을 slice를 이용하여 복사를 하면 각 인덱스에 대한 참조가 아닌 값 자체가 복사되기 때문에 원본 배열에 영향이 없었던 것이었다.
얕은 복사에 대한 정확한 이해를 위해 다시 chatGPT에게 물어봤다.
질문 : 그럼 배열의 원소들이 원시 값이 아닌 배열에 slice(0, 3) 이렇게 하면 복사본 배열은 각 요소가 참조를 갖고 있게 된다는 말이지?
답:
slice 메서드를 사용하면 얕은 복사가 수행되기 때문에, 복사본 배열의 요소들은 원본 배열의 요소에 대한 참조를 갖게 됩니다. 이는 배열의 요소가 원시 값이 아닌 객체나 배열일 때 특히 중요합니다.
예를 들어, 다음과 같은 코드에서:
let originalArray = [[1, 2, 3], [4, 5, 6]];
let shallowCopiedArray = originalArray.slice();
shallowCopiedArray[0][0] = 99;
console.log(originalArray); // [[99, 2, 3], [4, 5, 6]]
console.log(shallowCopiedArray); // [[99, 2, 3], [4, 5, 6]]여기서 originalArray의 첫 번째 요소는 배열 [1, 2, 3]이고, shallowCopiedArray는 originalArray의 얕은 복사본입니다. shallowCopiedArray[0][0] = 99;와 같이 복사본 배열의 내부 배열을 수정하면 원본 배열도 함께 수정됩니다. 이는 복사본 배열의 요소들이 원본 배열의 요소에 대한 참조를 가지고 있기 때문입니다.
그러니까 원래 얕은 복사를 하면 복사본 배열의 요소들은 원본 배열의 요소에 대한 참조 값을 갖고 있는게 맞다.
그럼 cow[i] = cow[i-1]도 얕은 복사인데 왜 얘는 cow[i] = cow[i-1].slice(0, 3)과 다른 결과가 나온건지 궁금해서 생각해보다가 내가 생각한 결론이 맞는지 물어봤다.
질문 : cow[i] = cow[i-1]로 하면 모든 원소가 동일하게 변경되었던 건 cow[i-1]의 요소 하나하나가 아닌 cow[i-1]에 대한 참조가 cow[i]에 들어가기 때문이었던거지?
답 :
맞습니다. cow[i] = cow[i-1]를 사용하면 cow[i]와 cow[i-1]는 같은 참조를 공유하게 됩니다. 이는 동일한 메모리 위치를 가리키기 때문에, cow[i]나 cow[i-1]를 통해 수행된 모든 변경 사항이 두 변수에 동시에 반영됩니다. 이 경우 두 변수는 동일한 배열을 가리키고 있기 때문입니다.
참조와 복사의 차이
- 참조 복사: 변수 A를 변수 B에 할당할 때, B는 A와 동일한 메모리 참조를 가집니다. 따라서, B를 통해 배열의 내용을 변경하면 A도 변경된 내용을 보게 됩니다.
let A = [1, 2, 3];
let B = A; // B는 A와 같은 참조를 가집니다.
B[0] = 99;
console.log(A); // [99, 2, 3]
console.log(B); // [99, 2, 3]- 얕은 복사: 배열의 최상위 요소들만 복사됩니다. 내부 배열이나 객체는 여전히 원본 배열과 참조를 공유합니다.
let originalArray = [[1, 2, 3], [4, 5, 6]];
let shallowCopiedArray = originalArray.slice(); // 얕은 복사
shallowCopiedArray[0][0] = 99;
console.log(originalArray); // [[99, 2, 3], [4, 5, 6]]
console.log(shallowCopiedArray); // [[99, 2, 3], [4, 5, 6]]- 깊은 복사: 배열의 모든 요소들이 재귀적으로 복사됩니다. 이로 인해 내부 배열이나 객체도 새로운 참조를 갖게 됩니다.
let originalArray = [[1, 2, 3], [4, 5, 6]];
let deepCopiedArray = originalArray.map(innerArray => innerArray.slice()); // 깊은 복사
deepCopiedArray[0][0] = 99;
console.log(originalArray); // [[1, 2, 3], [4, 5, 6]]
console.log(deepCopiedArray); // [[99, 2, 3], [4, 5, 6]]
...내가 잘못 알고 있었던 거였다. cow[i] = cow[i-1]은 얕은 복사가 아닌 참조 복사로서, cow[i-1]와 cow[i]가 같은 메모리 주소를 가리키게 만드는 것에 불과했던 것이었다. 그러니까 이렇게 하면 cow[0]부터 cow[n-1]까지 같은 메모리를 가리키게 되기 때문에, for문을 모두 돌고 나서 cow[0]의 값을 수정하더라도 cow[1], cow[2], ...cow[n-1]까지 모두 수정되었을 것이다.
느낀 점
얕은 복사, 깊은 복사, 참조. 이런 건 다른 언어에서도 모두 있는 것이라서 대략 알고는 있었지만, 내가 정확히는 모르고 있었다는 걸 알았다. 이번 기회에 공부하게 되었으니 다음부터는 조심해야겠다.
'문제풀이 > 누적합' 카테고리의 다른 글
| [Python/파이썬] 백준 16507번 어두운 건 무서워 (0) | 2025.01.19 |
|---|---|
| [Python/파이썬] 프로그래머스 롤케이크 자르기 (0) | 2024.10.26 |
| [Python/파이썬] 백준 5549번 행성 탐사 (0) | 2024.06.08 |
| [Python/파이썬] 백준 20116번 상자의 균형 (0) | 2024.05.20 |
| [Python/파이썬] 백준 2876번 그래픽스 퀴즈 (0) | 2024.04.30 |